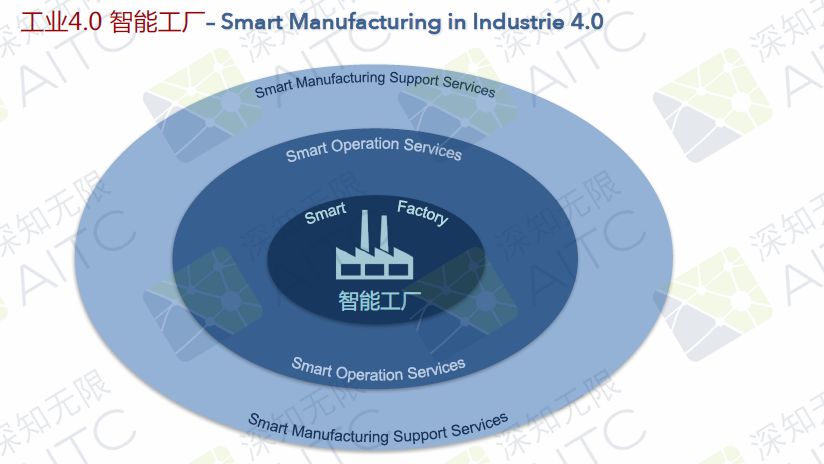
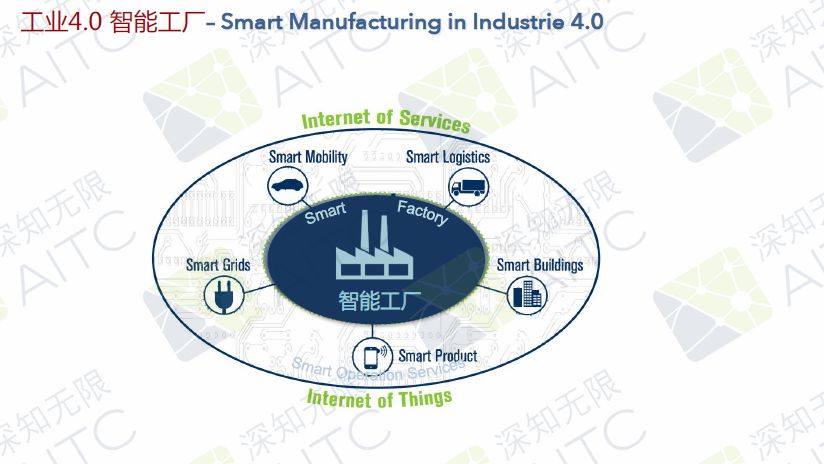
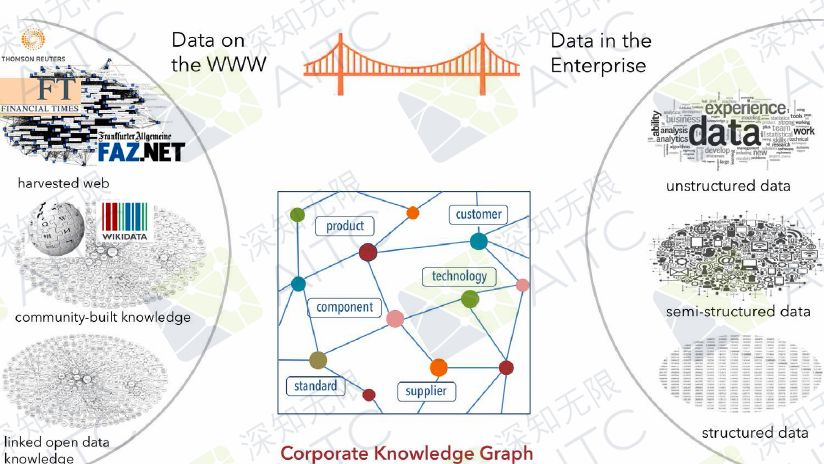
From May 19th to 20th, the 2018 Global Artificial Intelligence Technology Conference (GAITC) was held at the Beijing National Convention Center. Leaders of the world’s leading industries converged here to focus on AI hotspots to share the latest insights in the AI ​​field and lead the industry in the development of the industry. It is well known that Prof. Dr. Hans Uszkoreit, chief scientist of the Infinitely Artificial Intelligence Institute, serves as chairman of this conference. The following is a summary of the speech given by Academician Hans Uekkert: Industry 4.0 - Smart Factory ▶ 3 levels of Industry 4.0 Smart Factory: Smart Factory Smart Operation Service Smart Support Service ▶ Smart Factory Core First, network physical systems, including sensors, actors, and processors, are all connected to the Internet of Things. Through the input of data, we can do a lot of learning, and carry out a lot of translations and understandings of the pictures. We can also carry out relevant reasoning, and carry out rapid iteration and automation. Secondly, in Industry 4.0, there is one important point: Digital Twin technology - a digital model of a product or part with history/memory. Digital Twin mainly comes from the semantic product memory. In this concept, we think all parts should have a Digital Twin on their own machine. The models that were built at the beginning are not very good. They use some structured languages ​​and models. At the same time, people can also input their own language into Digital Twin. With Digital Twin, our machines can be used by people and can be used by the machines themselves. Third, flexible product-driven production configurations. For example, our product will tell our machine what steps it will take in the next step, for example, at which production site it will be processed last year. So I hope our entire system is flexible and very flexible, not very rigid. Fourth, intelligent robots and man-machine collaboration. Fifth, AI-based process optimization - predicting resource utilization. We can use predictive resources, not just predictive maintenance, but also predict our energy use, material usage, and predict all production-related resources. These are the learning conclusions that are obtained through our production with reality. At DFKI, we have cooperated with many factories and hope to put our technology and ideas into practice in these factories. ▶ Smart Operations Service The outer layer of the smart factory is an intelligent operation service. Now that there are smart travel, smart logistics, intelligent buildings, smart products, and smart grids, these are the facilities on the outer layer of the smart factory. They are closely related to production. For running services, its focus is equal to smart factory or intelligent manual production. ▶ Smart Support Services The third floor of the smart factory - smart support services, I think the most important thing for the factory is not in the factory, many people working in the factory think that the factory or product is the most important, but it is not the case. The final consumer of the product is the most important, as well as the supplier, etc. If my supplier stops supplying to me, the factory will stop production, and investors, regulators, technology providers, service partners, etc. are all very important. At the same time, language is also crucial. We need to get a lot of data from outside of all factories, and apply this data to our factories, such as product development, product upgrades, and production plans. For example, we want to see what the consumer needs are and what the consumer wants. What the pricing is, we also need to look at what we can get from the supplier, because if there is no supplier, we can't produce. There are many non-structured data here. The third floor to the first floor of the smart factory are interlinked. On the one hand, we need to translate a lot of data, language, and understand many data from different actors or partners. We also send data to partners (such as suppliers). We need to send them a lot of data to tell them what kind of specifications we need, so the whole structure is very complicated. Through such cooperation, smart product management, intelligent customer relationship management, smart product manager, intelligent investor management, intelligent supervisor management, smart market research, etc. can be obtained. How to get data from outside? There is a lot of data from the digital content of partners, including investors, governments, etc. Our external data requires the use of media, social media, open knowledge, and open data. E.g: Last year, Volkswagen had some problems with its suppliers. They did not receive timely warnings, and the public spent 14 months looking for alternative suppliers. 2 We previously worked with Siemens on a project where they had more than 190,000 direct suppliers and millions of indirect suppliers. We hope to use our technology to help them, such as the system to find out some early warning signals. Knowledge map We are the entire open database. We hope to make a bridge to connect the public and private knowledge bases. We hope to use them in the entire knowledge area, including different Wikipedia sites (such as Wikipedia) or other knowledge management projects. The private knowledge base is connected so that the bridge can be constructed in a knowledge map. For example, Google, Bing, Baidu and other different types of knowledge maps. In order to link internal and external knowledge bases, an internal knowledge map of the company is often constructed so that more possibilities are available. Wikipedia is very large and it is a huge database. However, there are only so many publicly released print editions of Wikipedia. This is why we really want to achieve online browsing or inquiries. This is because it is very difficult for a phonetician or a specialist in the field of knowledge to achieve a breakthrough if they all print. If we want to do some search and retrieval it will be very difficult, and some knowledge will not be translated into a knowledge map. I intercepted an example of the art field from Google's system. Provided by Google's knowledge map, it does not come from a single document, but a combination. NLP Technology for Big Data ▶ 2 problems with natural language understanding Language ambiguity The same sentence may have different understandings in some contexts. For example, one word or one sentence can have different interpretations. For example, if the word "put" is used, if there are many different understandings of the dictionary, or if the English language of the time flies, it will also have different understandings. There are thousands of ways for people to interpret the same thing. Everyone has a different interpretation, so it is very difficult to interpret and translate the language. We did a research in 2008. Microsoft bought the company Powerset. Actually it can use different words like buy, buy, or other words. It may just use very vague words, but we know they are Wholly-owned acquisitions, or even annexation. Different words can express the same meaning. For people, they can come up with different types of words. For example, people on social media or reporters may choose the best one based on their own content, but it is difficult for machine learning. We need to create a set of statistics-based machine learning, neuron learning, and the entire potential and challenges are unprecedented. If we learn these phrases, such as the acquisition of B by A, we need to let the machine understand whether he actually acquired a certain thing or whether he actually acquired a certain company. So we must extract the corresponding information from these sentences. For example, its price, the company involved, we need to extract the correct key phrase. And we need to highlight the most critical information, there are some simple information, simple information can be ignored, because it may change. So when we analyze corpus, we will use green to mark the most important information that we want the machine to learn. Super learning technology We will also perform specific semantic analysis based on the components of the neuron, and we will extract information for semantic screening. Because in one sentence, he said that Microsoft invested in the Powerset company. He used the term "investment," but we also need to do some screening and interpretation of the entire information. In this way, unstructured information can be truly structured. We have also published a lot of documents and corresponding patents before. We have also promoted the application of many industries. At present, we also have some cooperation projects in China. We are constantly updating and improving and we can now recognize Chinese. At the same time, we also hope to cover more languages. Absolute Linear Encoders,Custom Absolute Encoder,Rotary Encoder Magnetic,Miniature Absolute Encoder Yuheng Optics Co., Ltd.(Changchun) , https://www.yhencoder.com